It’s Complicated!
To most library staff, Linked Data seems complicated. That’s because it is. Unlike MARC, which came into being as a means of electronically representing records with a finite and controlled collection of fields, one of the driving forces behind the wider Linked Data movement is the desire to represent data in a more flexible fashion that need not, by definition, conform to a pre-defined data model.
Much effort has been, and continues to be, devoted to understanding the benefits of linked data for information consumers (such, as for example, students and scholars.) BIBFLOW’s focus is on understanding both the feasibility and impact of the adoption of Linked Data for library workers and work-flows. What possible benefits does Linked Data have to offer for library workers and administrators? How can we utilize linked data to improve our work effort and systems? In a recent post to the Library of Congress BIBFRAME Listserv, Karen Coyle noted, “Nowhere, however, do [we] see a serious discussion in the library data creation community of use cases and functional requirements.” BIBFLOW’s objective is to fill this knowledge gap—to consider Linked Data from the perspective of the ‘data creation community.’
Shifting Linked Data into institutional workflows is actually a more complex problem than that presented by the ontological differences between MARC and, for example, BIBFRAME. The below image represents an high level view of the ILS systems currently in place at UC Davis Library.
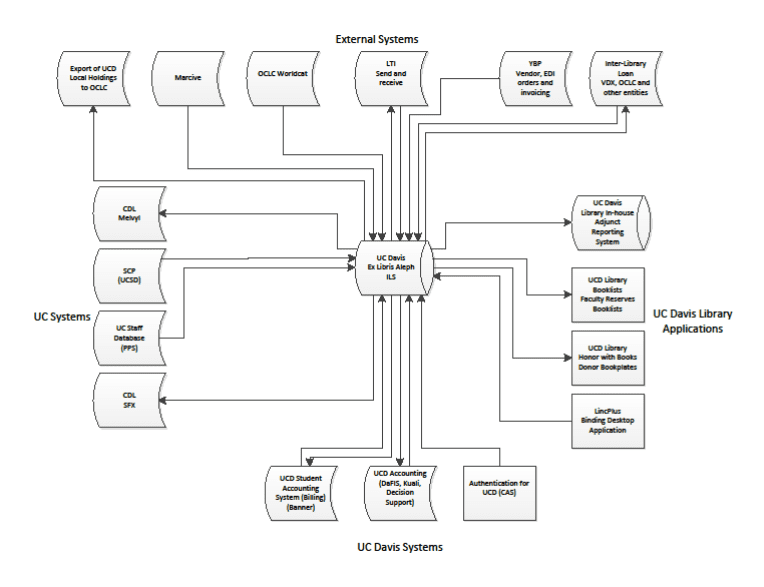
Additionally, the UCD Library Service Framework 2014-15 provides a breakdown of the basic data driven tasks performed by UC Davis Library staff.

As can be seen in the above two documents, all data, regardless of its form, has a complex, multi-departmental home even within an individual library (a situation that is amplified when sharing data across institutions). Additionally, we estimate that over 30 different software applications are currently employed at various nodes of identified library workflows.
This complexity leads to the inevitable conclusion that Linked Data represents an evolutionary leap for libraries and not a simple migration. Over the course of the project, we will work to drill down on various aspects of this complexity in order to provide a comprehensive roadmap of both current library workflow/technology dependencies and also of how (and when) to successfully shift workflows to Linked Data systems as a means of both improving workflow efficiencies and the quality of data.